Searching in Unicode files
Aba automatically recognizes UTF-8 and UTF-16 LE files and handles them appropriately.
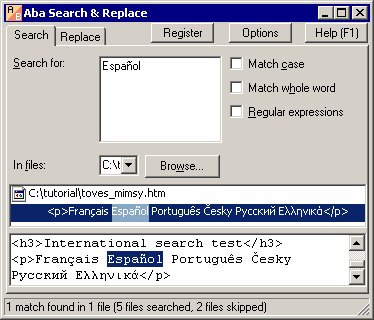
Troubleshooting Aba's encoding recognition
In rare cases, the file encoding may be recognized incorrectly and you will be unable to search for extended ASCII characters in the file.
If you have a problem with encodings, please type the regular expression ^^ to see all files in your folder and view them in the context viewer. If any of the files is displayed incorrectly, you should:
- for a plain text file, add Unicode byte order mark (BOM): just open the file in Notepad and save it (File > Save).
- for an HTML file, add
Metatag. For example, use the following tag for the code page 1252 (Latin-1, Western Europe):<meta http-equiv="Content-Type" content="text/html;charset=windows-1252">.
The encoding is shown in the right lower corner of the window (near to the selected file name), for example, file.htm, Win Latin-1 or file.htm, Unicode UTF-8.
The usual problem is specifying a wrong encoding in the Meta tag, for example, tagging Win Latin-1 file as ISO Latin-1. You should correct such tags, because the file will be incorrectly handled not only by Aba, but also by many web browsers.
This is a page from Aba Search and Replace help file.
- Welcome to Aba
- Getting started
- How-to guides
- Selecting the files to search in
- Inserting some text at the beginning of each file
- Replacing multiple lines of text
- Searching in Unicode files
- Replacing in binary files
- Performing operations with the found files
- Undoing a replacement
- Saving search parameters for further use
- Removing private data
- Adding or removing Aba from Explorer context menu
- Integrating Aba with Total Commander
- Integrating Aba with Free Commander
- Integrating Aba with Directory Opus
- Regular Expressions
- Replacement syntax
- User interface
- Command line
- Troubleshooting
- Glossary
- Version history
- Credits