Cleaning the output of a converter
18 Nov 2011
When I worked at a small web design company, we often had clients bringing us a MS Word, Excel, or PDF file that must be published on web. Not as a downloadable file, but as a web page integrated into their site.
Microsoft Word certainly can save files in HTML, but the resulting code was bloated and different from our design. What we needed was a simple HTML that our designer could edit and style. How could Aba S&R help us?
Here is a DOC file saved in HTML:
<h3 align=center style='text-align:center;'><b><span style='font-size:10.0pt;font-family:"Arial";'>Lorem ipsum</span></b></h3>
<p class=Normal align=justify style='text-indent:14.0pt;text-align:justify;'><span style='font-family:"Times New Roman";'>Lorem ipsum dolor sit <i>amet,</i> consectetur adipisicing elit.</span></p>
We need to remove all attributes and <span> tags:
<h3><b>Lorem ipsum</b></h3>
<p>Lorem ipsum dolor sit <i>amet,</i> consectetur adipisicing elit.</p>
The following replacements can be used:
Search for: <(p|h1|h2|h3) [^>]*> Replace with: <\1> Search for: <span [^>]*> Replace with: (nothing) Search for: </span> Replace with: (nothing)
[^>]* matches everything up to the next closing angle bracket >, and \1 means the text inside the first parentheses (in our case, the tag name).
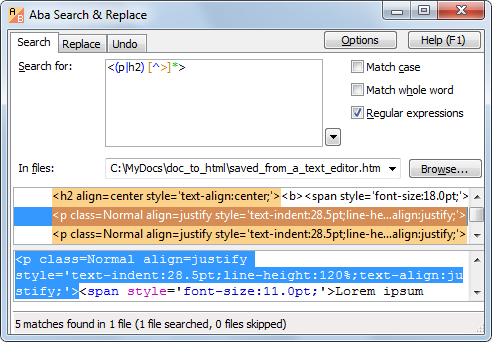
Generally, I often used Aba to clean the output of a converter. For one client, I had to convert dozens of PDF files with technical specifications to HTML. There was a lot of formatting (subscripts, superscripts, tables), so I could not simply copy-and-paste it. There also were errors, for example, the letter O instead of zero in subscripts. Without Aba, I would not clean this mess.
Is it a bad practice?
Two redditors criticized my previous post about using regular expressions to replace HTML tags.
I fully agree that regexes should never be used to parse an arbitrary HTML code, for example, an HTML code entered by user. Never do this in your scripts; it's unreliable and insecure.
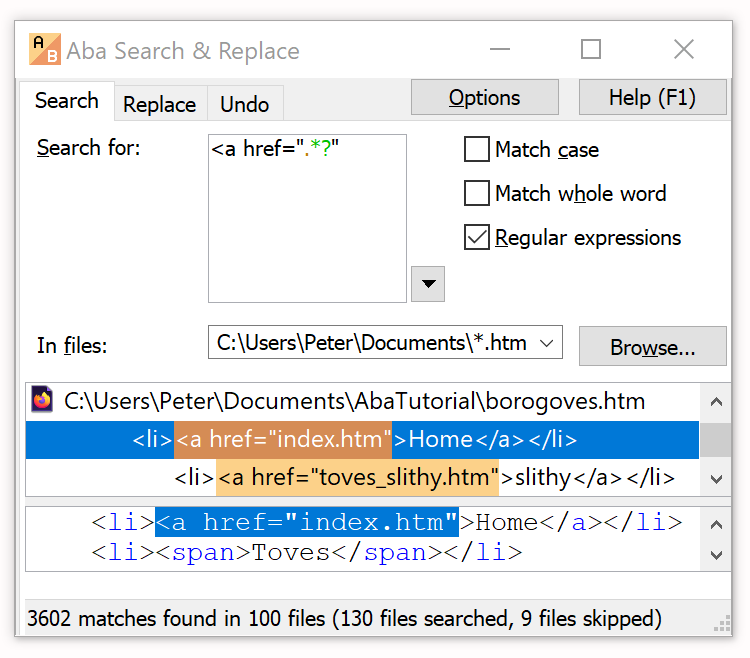
But what if you need to replace all relative links (/blog/) in your own code with absolute links (http://www.example.com/blog/), because you are moving some parts of your site to a subdomain (http://myproduct.example.com). Would you craft a script that parses your HTML code (carefully skipping <?php tags — Python's HTMLParser cannot do that), searches for all <a> tags with the href attribute, replaces the links, and saves the result to a file?
Or would you toss off a regex in a search-and-replace tool?

Replacing text in several files used to be a tedious and error-prone task. Aba Search and Replace solves the problem, allowing you to correct errors on your web pages, replace banners and copyright notices, change method names, and perform other text-processing tasks.
This is a blog about Aba Search and Replace, a tool for replacing text in multiple files.
- Regular Expressions 101
- Regular expression for numbers
- Aba 2.6 released
- Search from the Windows command prompt
- Empty character class in JavaScript regexes
- Privacy Policy Update - December 2022
- Aba 2.5 released
- Our response to the war in Ukraine
- Check VAT ID with regular expressions and VIES
- Which special characters must be escaped in regular expressions?
- Aba 2.4 released
- Privacy Policy Update - April 2021
- Review of Aba Search and Replace with video
- Aba 2.2 released
- Discount on Aba Search and Replace
- Using search and replace to rename a method
- Cleaning the output of a converter
- Aba 2.1 released
- How to replace HTML tags using regular expressions
- Video trailer for Aba
- Aba 2.0 released